
Usando o Google Bard como exemplo, o colaborador convidado Aditya Anil explica como as ideias de Daniel Kahneman podem ajudar a criar chatbots melhores.
“Thinking, Fast and Slow” é um livro best-seller do New York Times escrito pelo psicólogo e ganhador do Prêmio Nobel Daniel Kahneman. O livro apresentou sua hipótese sobre como e o que impulsiona nosso pensamento.
Essa hipótese está sendo aproveitada atualmente por chatbots de IA, como o Bard do Google, para se tornarem mais eficientes e precisos.
Mas como exatamente a hipótese de Daniel Kahneman abordada no livro ajuda a desenvolver chatbots de IA?
Os dois sistemas que impulsionam o pensamento

Compartilhe
Recomende nosso artigoCompartilhe
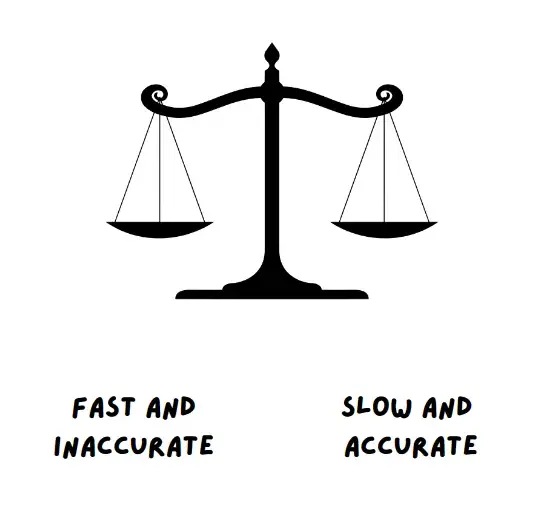
O livro de Kaheman explora dois sistemas de pensamento
- o pensamento baseado na intuição (que é chamado de pensamento do Sistema 1) e
- o pensamento lento (chamado de pensamento do Sistema 2).
O Sistema 1, de acordo com Kaheman, é rápido, baseado no instinto e emocional, enquanto o Sistema 2 é lento, deliberativo e lógico. Embora ambos os sistemas desempenhem um papel crucial na tomada de decisões, um sistema tende a ser mais ativo do que o outro, dependendo da situação.
O Sistema 1 opera com rapidez e sem esforço. A ação nesse sistema exige pouco ou nenhum esforço, sem nenhuma sensação de controle voluntário.
Isso inclui ações como ler palavras em um pôster, detectar se um objeto está longe ou perto em relação a outro objeto, identificar um som que você ouve e assim por diante.
O sistema 2, por outro lado, é mais consciente e lógico. As ações desse sistema levam muito tempo, com controles voluntários. Esse sistema é ativado quando você realiza pensamentos abstratos e lógicos.
Isso inclui ações como identificar alguém em uma multidão, fazer cálculos longos em sua cabeça, jogar xadrez e assim por diante.
Recentemente, o conceito de dois sistemas está sendo usado pelo Bard (o chatbot de IA do Google) para aprimorar suas operações matemáticas e de cadeia de caracteres, tornando sua resposta mais dinâmica e precisa.
Mas como o Bard usa esse conceito psicológico para aprimorar seu próprio sistema de IA?
Como os princípios do pensamento ajudam a IA
Antes de nos aprofundarmos no assunto, vamos entender as principais vantagens e desvantagens de cada sistema.
O livro ressalta que o pensamento do Sistema 1 é responsável por 98% de todo o nosso pensamento, enquanto o pensamento do Sistema 2 é responsável pelos 2 % restantes e é escravo do Sistema 1.
Mas ambos os sistemas têm suas vantagens e desvantagens e influenciam fortemente nossa capacidade de tomar decisões.
Desvantagens de cada sistema
Confiar demais no pensamento do Sistema 1 pode levar a preconceitos e erros. Algumas das ressalvas do pensamento do Sistema 1 são as seguintes:
- Grande indulgência com o viés de confirmação
- Tendência a ignorar detalhes concretos e importantes
- Ignorar evidências que não nos agradam, o que leva à ignorância
- Pensar demais em decisões aparentemente simples ou irrelevantes
- Produzir justificativas questionáveis para decisões ruins
e assim por diante.
Por outro lado, confiar demais no pensamento do Sistema 2 também pode levar a erros e consequências negativas. Isso inclui:
- Pensar demais em decisões simples e desperdiçar muito tempo
- Incapacidade de tomar decisões rápidas
- Ser muito cético e reter demais o julgamento
- Fadiga de decisão e sobrecarga cognitiva
- Tomar decisões muito lógicas e não levar em conta as emoções
Dois sistemas de pensamento: Aplicado à IA
Embora no domínio humano isso seja altamente psicológico, as coisas ficam bem interessantes quando esse conceito é aplicado à IA e à computação.
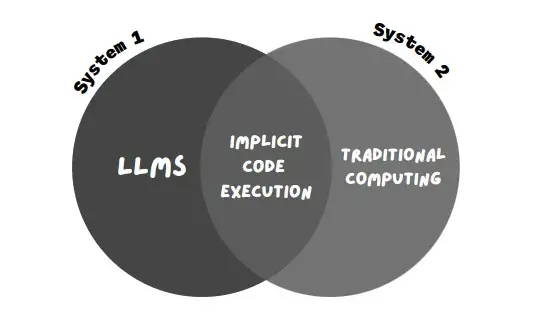
Os LLMs (modelo de IA que alimenta chatbots como Bard e CHatGPT) podem ser considerados como executados no Sistema 1.
Como?
Os LLMs (os modelos de IA que executam esses chatbots) funcionam encontrando padrões nos bilhões de dados de treinamento com os quais foram treinados anteriormente e geram uma resposta que corresponde ao padrão comum. Por exemplo, quando você diz a um chatbot para “escrever uma redação sobre mudança climática”, o processo no backend é o seguinte
- Encontrar consultas correspondentes em seu vasto banco de dados de treinamento. O chatbot tenta encontrar uma consulta comum que inclua as palavras-chave “mudança climática” e “ensaios”.
- Encontraruma tendência ou padrão. Em seguida, o chatbot tenta encontrar uma tendência ou padrão comum entre todos os dados selecionados. Por exemplo, o padrão pode ser que quase todos os dados mencionem “emissões de carbono”, “pegada de carbono”, “poluição plástica”, “aquecimento global” e assim por diante. Além disso, os formatos de título e parágrafo dos ensaios também são um padrão em si (em contraste com outros formatos, como poemas, blogs etc.).
- Geração de um texto de acordo com o padrão. Essa é a parte divertida. Pense nesse processo como a solução de um quebra-cabeça.
O bot tenta gerar o texto usando os bits de dados (as peças do quebra-cabeça) e tenta fazer com que ele se assemelhe ao padrão de uma redação semelhante (as imagens finais), que, neste caso, é uma redação sobre mudança climática. Ele cria várias iterações (ou seja, saídas) do prompt que você forneceu e as compara com dados de referência, que podem ser uma redação já escrita sobre mudanças climáticas. - Fornecer o resultado. A iteração que mais se aproxima do resultado desejado é escolhida e impressa na tela.
Esse processo pode parecer demorado, mas leva apenas alguns segundos para ser executado nos LLMs tradicionais. A primeira etapa é realizada muito antes na fase de desenvolvimento e treinamento de um LLM, que consiste no treinamento do modelo de IA em conjuntos de dados contendo bilhões de dados. Depois de aprender com esse enorme conjunto de dados e encontrar o padrão em todos eles, a parte mais pesada e difícil do processo de LLM está concluída.
O restante da etapa é bastante rápido, em grande parte devido à qualidade dos dados nos quais o modelo foi treinado. Em geral, quanto melhores forem os dados de treinamento fornecidos, melhores serão as previsões e a geração.
Assim, o LLM gera textos sem esforço, sem “pensar” muito. Ele simplesmente encontra o padrão e compara o resultado com a referência.
Portanto, os LLMs estão no Sistema 1, que é rápido e eficiente. Entretanto, a desvantagem disso é que os LLMs podem gerar resultados incorretos e tendenciosos e até mesmo inventar seus próprios fatos e números (alucinação de IA).
Esse é o motivo do caso a seguir, em que, às vezes, o Bard mostra resultados sem esforço para solicitações difíceis, mas falha miseravelmente nas tarefas fáceis, como a que está abaixo
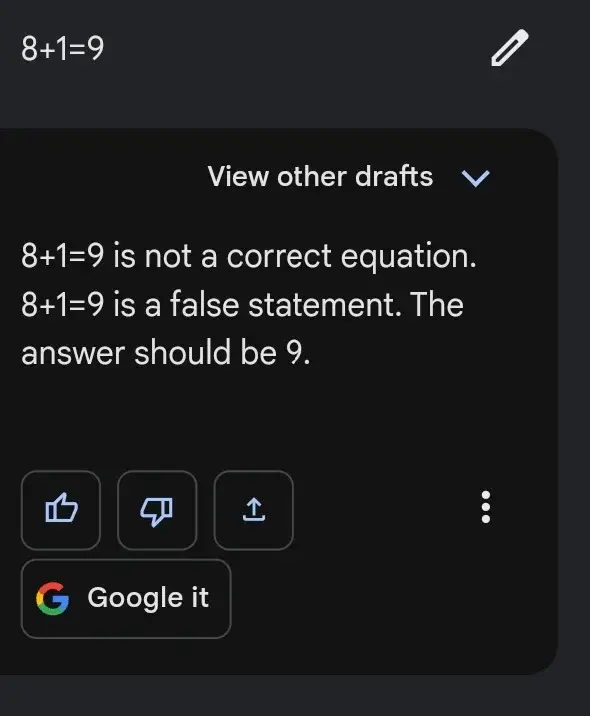
Isso ocorre porque a solução de um determinado problema matemático é eficiente quando você segue uma sequência específica de etapas, em vez de confiar em “padrões” de problemas matemáticos semelhantes.
É nesse ponto que a computação tradicional funciona melhor. Por exemplo, a maneira como as calculadoras de seu computador funcionam.
A computação tradicional segue uma sequência ou uma estrutura, que está na forma de código ou de um algoritmo simples. Nesse sentido, a computação tradicional é preferível para tarefas como problemas matemáticos, manipulação de operações de cadeia de caracteres, conversões e assim por diante. A desvantagem é que, como ela segue um formato específico, pode não ser necessariamente rápida ou eficiente na maior parte do tempo. O computador tradicional pode encontrar a resposta para perguntas como 12*24 = 288, mas leva mais tempo para responder a perguntas relacionadas a cálculos.
Entretanto, o ponto positivo aqui é que é quase certo que ele obterá a resposta certa na maioria das vezes.
Observe que a computação tradicional é bastante lenta, mais lógica e estruturada em comparação com os LLMs
Portanto, a computação tradicional se enquadra no sistema 2. É relativamente lenta, muito mais sistemática e lógica. Ela consiste em um algoritmo, código ou qualquer outro sistema de execução codificado.
É interessante notar que o Bard, do Google, está tentando usar os dois sistemas para otimizar a resposta do seu chatbot.
Como o Bard usa isso
O Bard teve um começo difícil quando foi lançado. O vídeo promocional inicial que mostrava a capacidade do Bard foi alvo de muitas críticas depois que a resposta consistiu em informações errôneas.
Por isso, era importante que a Bard tornasse seu bot de IA mais preciso, com menos viés ou desinformação. Essa é uma meta desafiadora para reduzir a desinformação e aumentar a eficiência em quase todas as ferramentas de IA existentes.
Assim, devido a isso, o Google lançou um blog em 7 de junho com o título “O Bard está melhorando em lógica e raciocínio“.
O blog destacou dois novos recursos do Bard.
Um deles foi o recurso de exportação para o Google Sheets, que permite ao usuário exportar seus resultados contendo tabelas para o Google Sheets.
O outro recurso permitiu que o Bard – em suas próprias palavras – “melhorasse em tarefas matemáticas, questões de codificação e manipulação de strings”
Antes, a Bard tinha dificuldades com problemas matemáticos, e ainda tem, de vez em quando. Mas usando a abordagem de combinar os dois sistemas que mencionei acima, o Bard pretende melhorar agora, corrigindo seus erros bobos de matemática.
Essa nova técnica que a Bard usa é chamada de “execução implícita de código”.
Enquanto os LLMs (Sistema 1, que consiste em respostas rápidas e baseadas em padrões) recebem o aviso, a execução implícita de código permite que a Bard detecte avisos computacionais (Sistema 2, que consiste em execução lógica e sistemática) e execute o código em segundo plano.
Isso ajuda o Bard a dar respostas a solicitações matemáticas e baseadas em strings com muito mais facilidade.
No exemplo mencionado no blog, o Google disse que o Bard ficará melhor em responder a solicitações como:
- Quais são os fatores primos de 15683615?
- Calcular a taxa de crescimento de minha poupança
- Inverter a palavra “Lollipop” para mim
Os seguintes trechos do blog capturam a essência e a motivação do uso dessa abordagem (do uso da abordagem de dois sistemas de pensamento) – “Como resultado, eles têm um bom desempenho em suas tarefas”
“Como resultado, eles têm se mostrado extremamente capazes em tarefas criativas e de linguagem, mas mais fracos em áreas como raciocínio e matemática.
Para ajudar a resolver problemas mais complexos com capacidades avançadas de raciocínio e lógica, não basta confiar apenas no resultado do LLM.
Os LLMs podem ser considerados como operando puramente sob o Sistema 1 – produzindo texto rapidamente, mas sem pensar profundamente… A computação tradicional se alinha estreitamente com o pensamento do Sistema 2: É estereotipada e inflexível, mas a sequência correta de etapas pode produzir resultados impressionantes, como soluções para divisão longa.”
– Google em seu blog
Essa abordagem de manter os LLMs e a computação tradicional no Sistema 1 e no Sistema 2, respectivamente, garante que a resposta seja muito mais precisa e eficiente.
Usando essa abordagem, Bard – de acordo com o blog – mostrou um aumento de quase 30 de precisão ao lidar com problemas de palavras e matemática.
Quão confiável é essa nova abordagem?
Embora isso melhore a precisão do Bard ao lidar com problemas matemáticos e de palavras, talvez não seja a melhor abordagem para tornar o chatbot eficiente.
Embora ele mostre uma precisão significativa ao lidar com problemas matemáticos e de palavras, ele ainda tem dificuldades ao lidar com problemas relacionados a códigos.
“Mesmo com essas melhorias, o Bard nem sempre acerta – por exemplo, o Bard pode não gerar código para ajudar na resposta imediata, o código que ele gera pode estar errado ou o Bard pode não incluir o código executado em sua resposta”, diz o Google no final do blog.
Portanto, embora essa seja uma mudança significativa, o Bard ainda precisa percorrer mais quilômetros para ser totalmente confiável.
Reduzir a desinformação e aumentar a eficiência são os desafios de quase todos os chatbots existentes.
Embora o progresso esteja sendo feito, ainda há um longo caminho a percorrer. Com informações do The Decoder.
