
O InternLM é um grande modelo de linguagem com 104 bilhões de parâmetros introduzido pelo Laboratório Nacional de IA da China, o Shanghai AI Lab, em parceria com a empresa de vigilância SenseTime.
A Universidade Chinesa de Hong Kong, a Universidade Fudan e a Universidade Jiaotong de Xangai também estiveram envolvidas no seu desenvolvimento. Em tarefas em língua chinesa, ele claramente supera o ChatGPT da OpenAI e o Anthropics Claude.
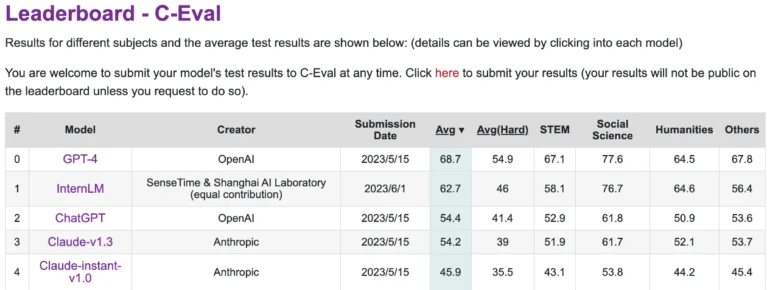
No entanto, ele fica atrás do GPT-4 no C-Eval, uma plataforma que avalia o desempenho de grandes modelos de linguagem em chinês. O InternLM foi treinado com 1,6 trilhão de tokens e, assim como o GPT-4, foi refinado para atender às necessidades humanas usando RLHF e exemplos selecionados. Ele é baseado em uma arquitetura de transformer semelhante à do GPT.
O treinamento foi baseado principalmente em dados do Massive Web Text, enriquecido com enciclopédias, livros, artigos científicos e código. Os pesquisadores também desenvolveram o sistema de treinamento Uniscale LLM, capaz de treinar de forma confiável grandes modelos de linguagem com mais de 200 bilhões de parâmetros em 2048 GPUs usando um conjunto de técnicas de treinamento paralelo.
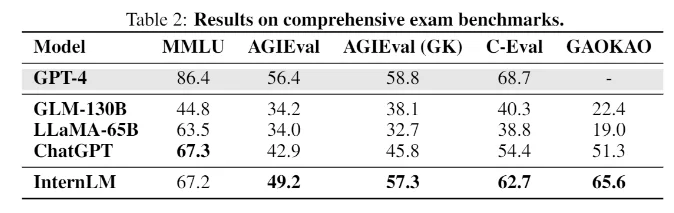
O InternLM alcança um desempenho equivalente ao ChatGPT em benchmarks de exames
Em benchmarks com tarefas que simulam exames humanos, como MMLU, AGIEval, C-Eval e GAOKAO Bench, o InternLM também atinge um desempenho comparável ao ChatGPT. No entanto, ele fica aquém do GPT-4, o que os pesquisadores atribuem à pequena janela de contexto de apenas 2000 tokens.
Em outras áreas, como recuperação de conhecimento, o modelo fica atrás dos melhores modelos da OpenAI. Modelos de linguagem de código aberto populares, como o LLaMA da Meta com 65 bilhões de parâmetros, têm um desempenho inferior ao do InternLM nos benchmarks.
A equipe ainda não publicou o modelo de linguagem, até o momento, apenas a documentação técnica está disponível. No entanto, a equipe escreve no Github que planeja compartilhar mais com a comunidade no futuro, sem fornecer detalhes.
Independentemente disso, o InternLM oferece uma visão interessante do estado atual da pesquisa chinesa em modelos de linguagem em grande escala, presumindo que o Laboratório Nacional de IA e a SenseTime tenham feito o seu melhor trabalho até o momento. “Em direção a um nível mais elevado de inteligência, ainda há um longo caminho a percorrer”, escreve a equipe de pesquisa.
