
Os pesquisadores usaram uma tarefa de texto simples para mostrar que os modelos de linguagem atuais falham quando se trata de conclusões lógicas básicas. Mas os modelos insistem em respostas erradas e superestimam suas habilidades.
Usando uma tarefa de texto fácil, pesquisadores do laboratório de IA LAION, do Jülich Supercomputing Center e de outras instituições descobriram falhas graves no raciocínio lógico dos modelos de linguagem modernos.
O problema é um quebra-cabeça simples que a maioria dos adultos, e provavelmente até mesmo crianças do ensino fundamental, poderia resolver: “Alice tem N irmãos e M irmãs. Quantas irmãs tem o irmão de Alice?”
A resposta correta é a adição de M + 1 (Alice mais suas irmãs). Os pesquisadores variaram os valores de N e M, bem como a ordem dos irmãos no texto.
Eles alimentaram o quebra-cabeça com modelos de linguagem pequenos e grandes, como GPT-4, Claude, LLaMA, Mistral e Gemini, que são conhecidos por suas habilidades de raciocínio lógico supostamente fortes.
Os resultados são decepcionantes: a maioria dos modelos não conseguiu resolver a tarefa ou só a resolveu ocasionalmente. As diferentes estratégias de solicitação não alteraram o resultado básico.
Somente o GPT-4 e o Claude conseguiram, às vezes, encontrar a resposta certa e apoiá-la com uma explicação correta. Mas, mesmo com eles, a taxa de sucesso variou muito, dependendo do texto exato do prompt.
No geral, a taxa média de respostas corretas dos modelos de linguagem ficou bem abaixo de 50%.
Somente o GPT-40 teve um desempenho acima do esperado, com 0,6 respostas corretas. Em geral, os modelos de linguagem maiores tiveram um desempenho muito melhor do que os pequenos, o que levou os pesquisadores a comentar: “Se for pequeno, vá para casa”.
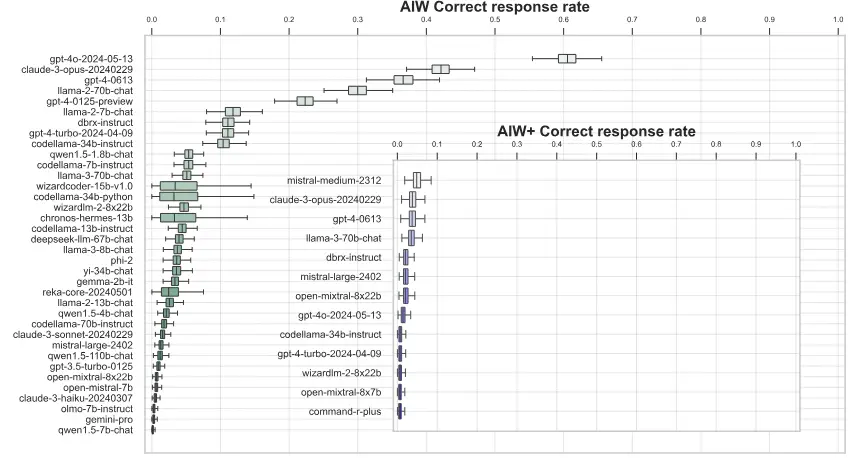
Uma versão mais difícil da tarefa (AIW+) levou até mesmo os melhores modelos Mistral Medium, GPT-4 e Claude 3 Opus à beira do colapso mental total, com pouquíssimas respostas corretas.
O que torna esse colapso ainda mais dramático é que os modelos expressaram forte confiança em suas respostas incorretas e usaram pseudo-lógica para justificar e apoiar a validade de respostas claramente incorretas, de acordo com o artigo.
O fato de os LLMs falharem nessa tarefa simples é ainda mais surpreendente quando se considera que os mesmos modelos têm bom desempenho em referências comuns de raciocínio lógico. A simples tarefa “Alice” deixa claro que esses testes em todo o setor não revelam os pontos fracos dos modelos, afirmam os pesquisadores.
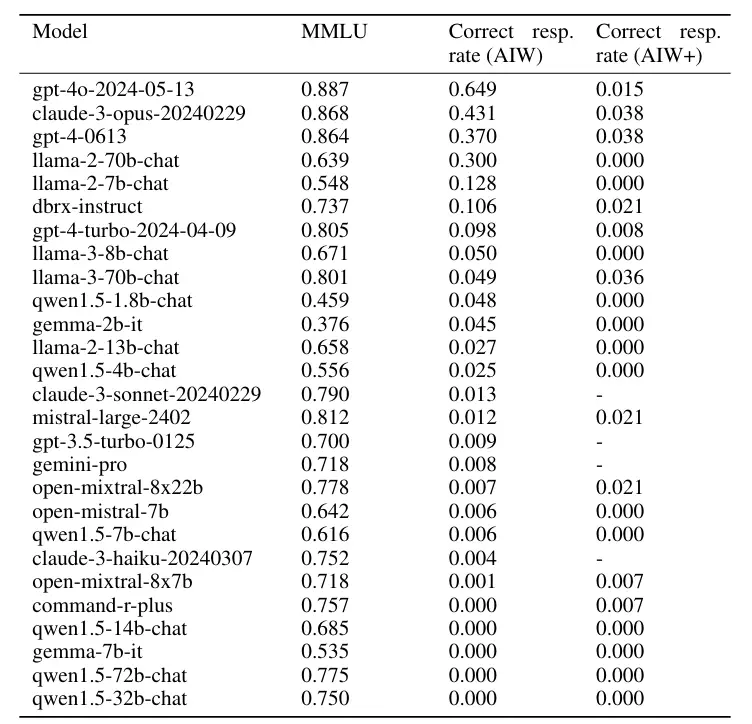
A equipe de pesquisa acredita que, embora os modelos tenham uma capacidade latente de tirar conclusões lógicas, eles não conseguem fazer isso de forma robusta e confiável. Isso requer mais estudos.
No entanto, está claro que os benchmarks atuais não refletem com precisão os verdadeiros recursos dos modelos de linguagem, afirmam eles, e pedem à comunidade científica que desenvolva testes melhores que detectem falhas lógicas.
“Nossa hipótese é que as habilidades de generalização e raciocínio central estão, portanto, presentes de forma latente nesses modelos, pois, caso contrário, eles não seriam capazes de gerar tais respostas, já que é impossível adivinhar a resposta correta, incluindo o raciocínio correto completo, por acidente nesses casos. O fato de que as respostas corretas de raciocínio são raras e o comportamento do modelo não é robusto às variações do problema demonstra uma deficiência no exercício do controle adequado sobre esses recursos.”
Do artigo
Um estudo anterior mostrou como os LLMs são fracos nas inferências lógicas mais simples.
Embora os modelos de linguagem conheçam a mãe do ator Tom Cruise, eles não conseguem descobrir que Tom Cruise é filho da mãe. Essa chamada “maldição da reversão” ainda não foi resolvida.
Outro estudo recente mostra que os modelos de linguagem agem de forma mais irracional do que os humanos quando tiram e justificam conclusões incorretas.
