
O 3D-LLM integra o entendimento de ambientes em 3D em grandes modelos de linguagem, levando os chatbots do mundo bidimensional para o mundo tridimensional.
Grandes modelos de linguagem e modelos de linguagem multimodal podem lidar com fala e imagens 2D, como ChatGPT, GPT-4 e Flamingo. No entanto, esses modelos carecem de uma compreensão real de ambientes em 3D e espaços físicos. Pesquisadores propuseram agora uma nova abordagem chamada 3D LLMs para resolver esse problema.
Os 3D LLMs são projetados para fornecer à IA uma ideia de espaços tridimensionais usando dados em 3D, como nuvens de pontos como entrada. Dessa forma, modelos de linguagem multimodal podem entender conceitos como relações espaciais, física e affordances que são difíceis de compreender apenas com imagens 2D. Os 3D LLMs poderiam capacitar assistentes de IA a navegar, planejar e agir melhor em mundos em 3D, por exemplo, em robótica e IA incorporada.
A relação entre o mundo 3D e a linguagem
Para treinar os modelos, a equipe precisava coletar um número suficiente de pares de dados em 3D e linguagem natural – tais conjuntos de dados são limitados em comparação com pares de imagens e texto disponíveis na Web. Portanto, a equipe desenvolveu técnicas de estímulo para o ChatGPT, a fim de gerar diferentes descrições e diálogos em 3D.
O resultado é um conjunto de dados com mais de 300.000 exemplos de texto em 3D, abrangendo tarefas como rotulagem em 3D, resposta a perguntas visuais, decomposição de tarefas e navegação. Por exemplo, o ChatGPT foi solicitado a descrever uma cena de quarto em 3D fazendo perguntas sobre objetos visíveis de ângulos diferentes.

A equipe conecta descrições de texto a pontos no espaço 3D
Em seguida, eles desenvolveram extratores de características em 3D para converter dados em 3D em um formato compatível com modelos de linguagem pré-treinados em visão 2D, como BLIP-2 e Flamingo.
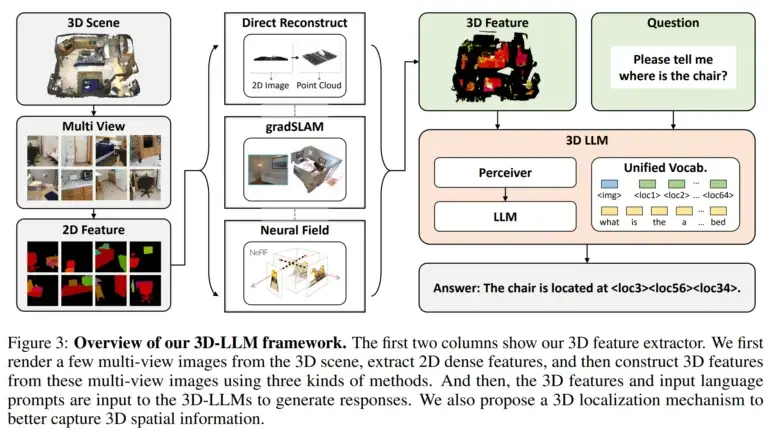
Além disso, os pesquisadores utilizaram um mecanismo de localização em 3D que permite que os modelos capturem informações espaciais associando descrições textuais com coordenadas em 3D. Isso também facilitou o uso de modelos como o BLIP-2 para treinar eficientemente os 3D LLMs a entenderem cenas em 3D.
Testes com o modelo de linguagem 3D mostraram resultados promissores
Os experimentos demonstraram que os modelos de linguagem 3D foram capazes de gerar descrições em linguagem natural de cenas em 3D, realizar diálogos conscientes de 3D, decompor tarefas complexas em ações em 3D e relacionar linguagem a localizações espaciais. Isso demonstra o potencial da IA para desenvolver uma percepção mais semelhante à humana de ambientes em 3D, incorporando capacidades de raciocínio espacial, de acordo com os pesquisadores.
Os pesquisadores planejam estender os modelos para outras modalidades de dados, como som, e treiná-los para executar tarefas adicionais. Eles também afirmam que o objetivo é aplicar esses avanços a assistentes de IA incorporada que possam interagir inteligentemente com ambientes em 3D. Com conteúdo do The Decoder.
