
新しいデータセットにより、ディープマインドは他の多くの機関と提携し、ロボット訓練におけるデータギャップを埋め、あらゆるタイプのロボットでロボット能力の一般化を可能にする。最初の結果は有望である。
グーグル・ディープマインドは、33の学術研究所と協力し、さまざまなタイプのロボットでロボット工学の汎化学習を促進するように設計された新しいデータセットとモデルを発表した。
データは22種類のロボットから得られたものだ。その目的は、異なるタイプのロボット間で能力をよりよく汎化できるロボットモデルを開発することである。
汎用ロボットを目指して
これまでは、タスクごと、ロボットごと、環境ごとに個別のロボットモデルを学習させる必要があった。これには多くのデータ収集が必要だ。さらに、ディープマインド社によれば、1つの変数が少しでも変わると、そのプロセスを最初からやり直さなければならなかった。
Open-Xイニシアチブの目的は、さまざまなロボット(企業)に関する知識を集め、普遍的なロボットを訓練する方法を見つけることだ。このアイデアが、Open-Xの具現化データセットと、RT-1(Robotic Transformer-1)から派生し、新しいデータセットで訓練されたロボット変形モデルであるRT-1-Xの開発につながった。
5つの異なる研究室でのテストでは、RT-1-Xが5つの一般的なロボットの制御を行った場合、ロボット固有の制御モデルと比較して、タスク完了の成功率が平均50%向上することが示された。
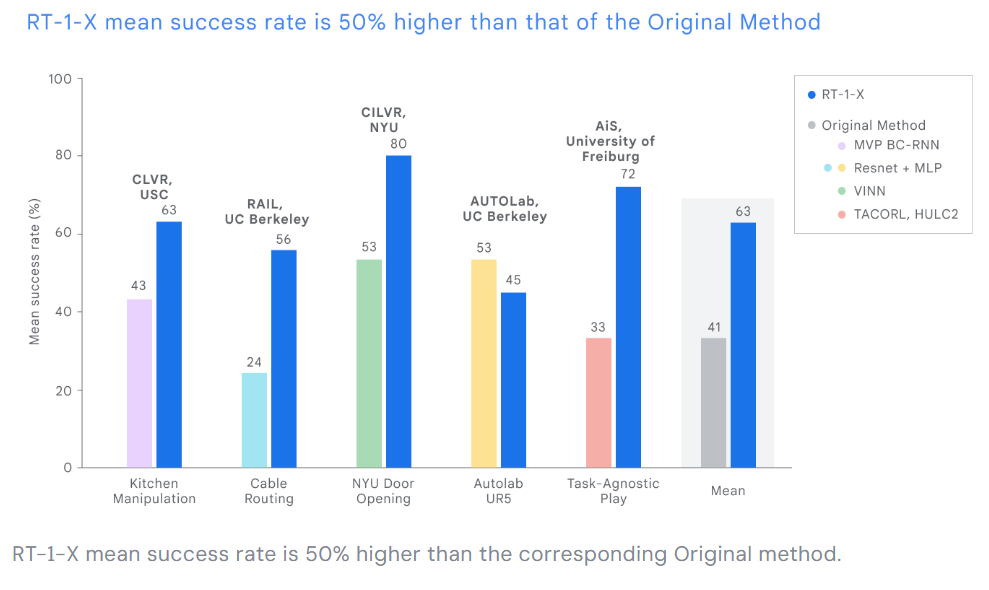
汎用ロボットのトレーニング用データセット
Open X Embodimentデータセットは、20以上の研究機関の学術研究室と共同で開発された。100万以上のワークフローで500以上の能力と15万以上のタスクを表現する22台のロボットのデータが集約されている。
ディープマインド社によると、このデータセットは、多くの種類のロボットを制御し、さまざまな指示を解釈し、複雑なタスクについて基本的な推論を行い、効率的に汎化できるジェネラリストモデルを訓練するための重要なツールだという。
ロボットモデルの新機能
この夏に発表されたRT-2-X視覚言語アクションモデルのRT-2バージョンは、Open-Xデータセットで訓練された後、潜在的な実世界ロボットとしての能力が3倍になった。この実験では、他のプラットフォームからのデータとの協調学習により、RT-2-XにオリジナルのRT-2データセットにはない追加機能が与えられたことが示されました。
RT-2モデルは、推論と行動の基礎として大規模な言語モデルを使用します。例えば、なぜ石が紙切れより良い即席ハンマーなのかを推論し、この能力を異なる応用シナリオに適用することができる。
データセットXでのトレーニング後、RT-2-Xはこれらの能力を向上させることができた。例えば、RT-2-Xは物体間の空間的関係をよりよく理解し、「リンゴを布の上に置く」「リンゴを布の近くに置く」といった細かいグラデーションを区別できるようになった。
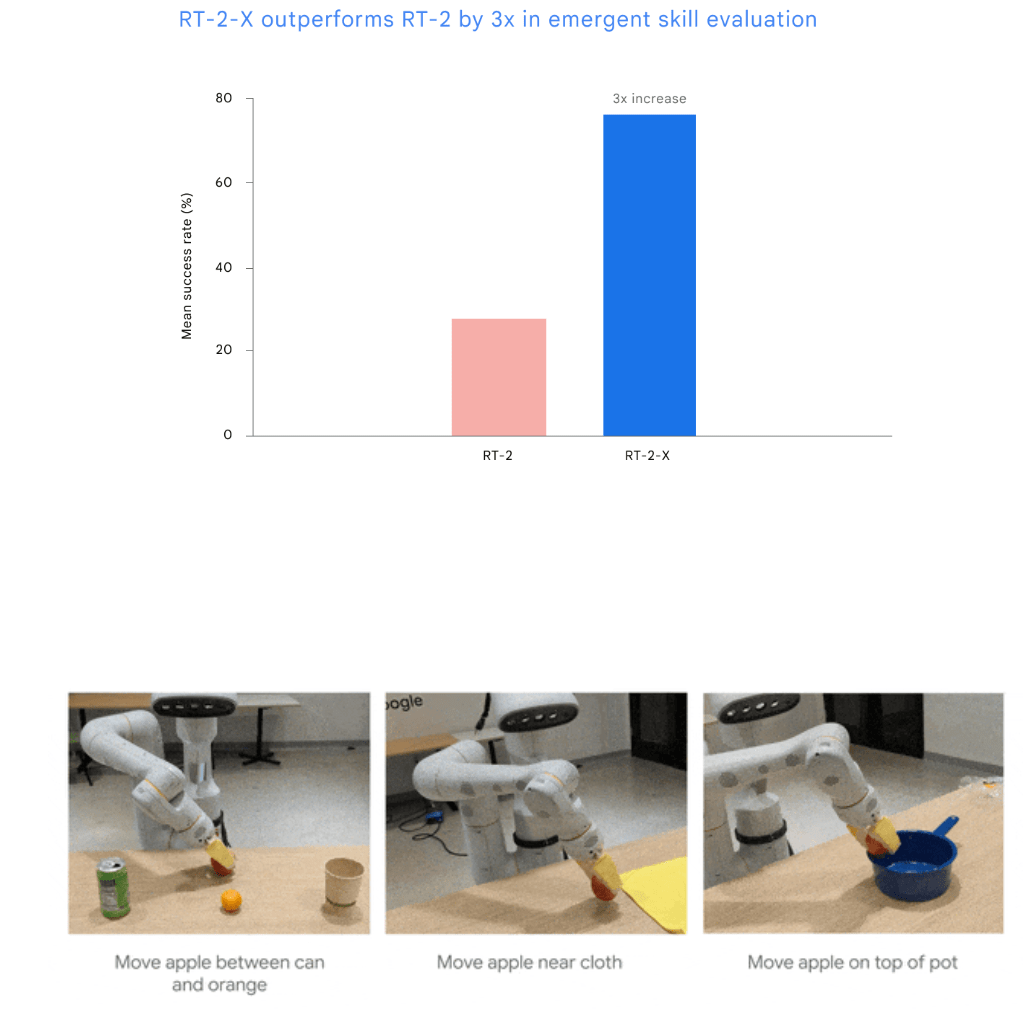
RT-2-Xは、他のロボットからのデータを使って訓練することで、すでに多くのデータを使って訓練された有能なロボットも改善できることを示している、とDeepmindは書いている。
研究チームの結論も同様で、異なるタイプのロボットからのデータを使ってロボットの能力をスケールアップすることはうまくいき、「劇的な性能向上」をもたらすという。今後の研究では、ロボットのモデルが経験からどのように学習し、自身を向上させることができるかを分析することができるだろう。
